In the previous post, we explored the theory and reality of feature management over the last 5-10 years and explored what improvements could be made in order to better suit the current situation for engineers and businesses. Now that we’ve envisioned this unified feature management system that can handle all of our use cases, we need to make sure that the architecture is appropriate.
The common managed service model is probably not going to work, primarily for availability reasons; while they usually provide a degree of client-side caching that can insulate us from very short outages, anything longer than a few seconds probably breaks a lot of our long-lived feature flag use cases.
Rolling our own system is also probably not going to go well, simply because our organization probably doesn’t have the appetite to put resources towards a system that is both feature-rich and reliable.
Is there a third option, that gives us the feature depth that we would get with a managed service, combined with the reliability and availability we’d get from a homegrown system? One approach might be a read-optimized hybrid system, where the managed service component mainly functions as a control panel for a system that runs close to or within our application with the assistance of tooling from the service provider.
This model moves more business logic into the application through a client library provided by the managed service provider. This client library would integrate with the web layer of my application to expose an API that the managed service can access to make writes, and would integrate with the data layer of my application to store data in its own tables within my database. When flags are checked, this same client library would access these same tables to resolve the feature flag, never reaching out to the managed service. The data stays within the application, ensuring low latency and high reliability. If the managed service goes down, flag resolution logic might become stale but not necessarily incorrect.

This type of model might be preferred by monolithic applications in large web frameworks like Ruby on Rails. In this context, the framework would provide a lot of the integration points to support easily installing such an integration architecture.
In some architectures, particularly those relying on microservices, it may be more convenient to run a separate service that can be deployed within my hosting environment. This service would act as a proxy to the service provider's API, constantly updating data from the service provider. In the case of an outage, we’re again relying on slightly outdated data which is likely correct for most users, making us tolerant to longer outages by the service provider.
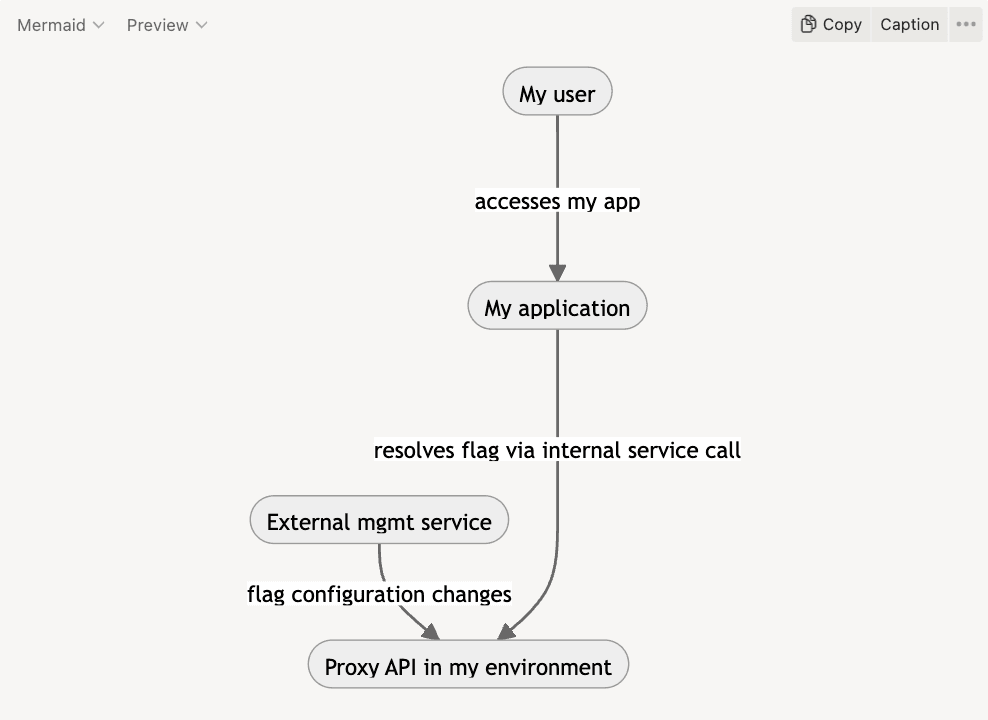
Similar architectures are offered by some feature management tools, however they’re generally positioned as niche techniques for enterprise use cases. Based on the assumptions laid out throughout this and the previous blog post, we posit instead that a hybrid model like these examples should be the default architecture for feature management.This is only the start, though. In future explorations of this topic, we’ll discuss aspects like:- Business context for feature flags- Verifiability and testing- Needs and requirements for different types of short- and long-lived feature flags
